Home · Book Reports · 2018 · Clean Code

- Author :: Richard C. Martin
- Publication Year :: 2009
- Read Date :: 2018-09-03
- Source :: Clean_Code.pdf
designates my notes. / designates important.
Thoughts
Overall I liked this book a lot. It was well structured and easy to read. There was the self-proclaimed “feel good” part of the book, but this was supported by some detailed case-studies that showed, literally step-by-step, the process the author took in cleaning up real-world code.
Cleaner is faster. This reminded me of the old racing adage: slower is faster. If you make a mess of your code to meet a deadline, it might feel like you are moving faster, but you are immediately slowed down on your very next edit by the mess. To maintain clean code requires thinking, refactoring, and is generally slower, but, in the long run, the cleaner the code the more rapidly you will be able to modify it in the future.
Every little thing adds up, in the end, to a big thing. A few dirty lines here and there will accumulate into what the author calls code rot. If you see one mess bit of code, and don’t clean it up, you might be tempted to leave another piece messy. This is kind of like a building with no broken windows will likely remain a building with no broken windows, but when one window is broken, the rest are subsequently broken. If no one cares about the broken window, why not break more?
This said, it is harder (and slower) to write clean code. But if you consider how many times code is written versus how many times it is read, it should be obvious that it should be this way. It is better to have easy to read code that was hard to write than easy to write code that is hard to read.
The number one take-away in the entire book, in my opinion, is to use meaningful names. It sounds so simple, but meaningful names are the best way to self document your code; to give explicit meaning to the code itself. The author, rightfully, belabors this point throughout the book, suggesting that names should be selected as carefully as choosing a name for a baby.
If nothing else, the cost of reading this book is paid for by this single gem:
The length of a name should correspond to the size of its scope.
Chapter three covers functions. The core advice is that smaller is better and each function should do one thing and do it well. This is a throwback to UNIX philosophy and one I agree with wholeheartedly.
Also, you should avoid side effects like the plague. Do one thing! This is coming more into its own now-a-days with the rise in functional programming as a response to the multi-core processors that have become ubiquitous and look to only increase in core count and possibly decrease in individual speed.
One argument per function is better than two, and two is better than three. Be careful when using more than two. Flag arguments scream out that the function should be decomposed; it must do two things if there is a flag.
Chapter four can be summed up by the opening quote:
“Don’t comment bad code– rewrite it” -Brian W. Kernighan and P. J. Plaugher
The take away here is that code should be readable without comments. With wise choices for variable names the code can tell you everything and more than a comment. When new programmers are taught to comment everything, it often leads to going overboard, cluttering the code with redundancy. You never want to see something as cringe worthy this:
count++; //increment count
Chapter five, on horizontal and vertical formatting, is a bit more subjective, but generally agreeable.
The main idea here is to get the code to read from top to bottom, much like a book, instead of making you jump all over to follow the flow path.
If one function calls another, they should be vertically close, and the caller should be above the callee, if at all possible. This gives the program a natural flow.
In short, similar things should be grouped horizontally. Functions that are called in other functions should follow the caller (opposite of C).
The line length should be limited. In a small sampling of code, most lines fell in the 20-60 character length range. It is ok to go to 100 or even a bit more on occasion.
It is also suggested to use horizontal formatting to group just like you would vertical. For example:
-b - a*c //makes sense, group mathematically
-b-a*c //the same computation, but harder to understand
Chapter six looks at objects and data structures. This is one of the most important parts so far, in my opinion.
Objects hide their data behind abstractions and expose functions that operate on that data. Data structure expose their data and have no meaningful functions.
Procedural code (code using data structures) makes it easy to add new functions without changing the existing data structures. OO code, on the other hand, makes it easy to add new classes without changing existing functions.
The complement is also true:
Procedural code makes it hard to add new data structures because all the functions must change. OO code makes it hard to add new functions because all the classes must change.
Chapter seven is short and sweet: don’t use error codes, handle exceptions.
Chapter eight deals with the boundaries of code. It also puts forth a nice way to learn new code: learning tests. You can write tests for a new API as you learn it. This will give you both a hands-on learning experience as well as leave you with a suite of tests that can be run when new versions of the API are released, verifying there were no changes that might bite you later.
Chapter nine continues the testing theme with unit tests. The main rule here is that tests should be kept as clean as the code. Do no look at tests as secondary, they are as, or more, important than the code itself.
Without good tests you are afraid to make changes. “What if this breaks something that isn’t caught until runtime?” Good tests allow you to make changes with near impunity. Make a change, test it out. You get immediate feedback letting you know if you broke something.
Chapter ten covers classes. There isn’t much to say about it.
Chapter eleven looks at system design.
It is a myth that we can get systems “right the first time.” Instead, we should implement only today’s stories, then refactor and expand the system to implement new stories tomorrow.
I disagree with this and think you can get it right the first time. Physical systems are given as an example that shows you can do this. One example is: buildings. You have to get a building, particularly a large skyscraper, right the first time. You can’t very well refactor it at a later date.
The argument is given that you CAN refactor code, but I don’t think that means you should. The ability should not be overlooked, but it should also not be seen as inevitable. The argument for refactoring is that business needs change and the demands of the software change. I can’t argue with either of these, but, following the UNIX philosophy, shouldn’t we write a single piece of software that solves one aspect of the business demands? When the demands change, we don’t refactor, we write another program. It should be noted that the programs I am suggesting are, again following the UNIX philosophy, small and to the point. They should work individual as well as allowing them to be piped together.
This isn’t to say certain libraries might be shared among these programs, but, as far as I can see, the constant flux most software is in is a huge shortcoming of developers. In no other industry would such constant change be accepted. This book rails on and on about professionally, then inexplicably forgoes the professionally of delivering a product that does what it is supposed to do and instead urges us to enter into an arms race with ourselves; always ‘improving’ and updating the code, always trying to keep a handle on the spiraling complexity.
I also think this is another reason why functional programming is coming into fashion. You write extremely small functions and chain them together to get larger effects, which is exactly how I think programs should be written. Mircoservies and other fads seem like that is what they want to do already, but are unwilling to take it to the extreme.
One part of this chapter I can agree with is:
Whether you are designing systems or individual modules, never forget to use the simplest thing that can possibly work.
Chapter twelve covers emergence.
Chapter thirteen offers some insight surrounding concurrency.
There are three main concurrency problems: producer-consumer, reader-writer, and dining philosophers. Each of these is examined in glancing detail.
Writing tests for concurrent code is hard. That said, when you do get a failure, that might not fail if you run the same test again, even a hundred times, you should take it as a sign that there is a flaw in your code. It might work most of the time, maybe even 99.9999% of the time, but there is a problem, probably with concurrency. There are a few tips for writing tests for concurrency presented as well as a third party tool that can help.
Chapter fourteen looks at, step by step, successive refinement. It is presented as a case study of the development of a command line argument parser.
Chapter fifteen is another case study. This time looking at the JUnit internals.
Chapter sixteen is yet another case study. It looks at refactoring a Java library: SerialDate. Honestly I only skimmed this chapter, but it looks as detailed as the other case studies and is probably worthy of study. I was simply tired of mucking around in Java code.
Chapter seventeen, the last chapter, looks at code smells and heuristics. It includes lots of guiding principles, however incomplete, to give you a feel for what to look for. The tree main take-aways in my opinion are:
Names in software are 90 percent of what make software readable. You need to take the time to choose them wisely and keep them relevant. Names are too important to treat carelessly.
the more you can use names that are overloaded with special meanings that are relevant to your project, the easier it will be for readers to know what your code is talking about.
The length of a name should be related to the length of the scope. You can use very short variable names for tiny scopes, but for big scopes you should use longer names.
Appendix A offers a more detailed look at concurrency.
Table of Contents
- Foreword
- 01: Clean Code
- 02: Meaningful Names
- 03: Functions
- 04: Comments
- 05: Formatting
- 06: Objects and Data Structures
- 07: Error Handling
- 08: Boundaries
- 09: Unit Tests
- 10: Classes
- 11: Systems
- 12: Emergence
- 13: Concurrency
- 14: Successive Refinement
- 15: JUnit Internals
- 16: Refactoring SerialDate
- 17: Smells and Heuristics
- Appendix A: Concurrency 2
- Pages numbers from the pdf.
· Foreword
page 22:
-
As Fred Brooks admonishes us, we should probably re-do major software chunks from scratch every seven years or so to sweep away creeping cruft. Perhaps we should update Brooks’ time constant to an order of weeks, days or hours instead of years.
-
Going in I am already terrified. I take the whole other side of this. Write something that will work untouched for a decade.
· 01: Clean Code
page 45:
- the ratio of time spent reading vs. writing is well over 10:1. We are constantly reading old code as part of the effort to write new code. Because this ratio is so high, we want the reading of code to be easy, even if it makes the writing harder.
· 02: Meaningful Names
page 53:
- The length of a name should correspond to the size of its scope.
· 03: Functions
page 62:

page 67:
- way to know that a function is doing more than “one thing” is if you can extract another function from it with a name that is not merely a restatement of its implementation [G34].
page 76:
- Functions should either do something or answer something, but not both. Either your function should change the state of an object, or it should return some information about that object.
page 78:
public void delete(Page page) {
try {
deletePageAndAllReferences(page);
}
catch (Exception e) {
logError(e);
}
}
private void deletePageAndAllReferences(Page page) throws Exception {
deletePage(page);
registry.deleteReference(page.name);
configKeys.deleteKey(page.name.makeKey());
}
private void logError(Exception e) {
logger.log(e.getMessage());
}
page 78:
-Functions should do one thing. Error handing is one thing. Thus, a function that handles errors should do nothing else. This implies (as in the example above) that if the keyword try exists in a function, it should be the very first word in the function and that there should be nothing after the catch/finally blocks.
· 04: Comments
page 84:
- “Don’t comment bad code– rewrite it.” -Brian W. Kernighan and P. J. Plaugher
· 05: Formatting
page 108:
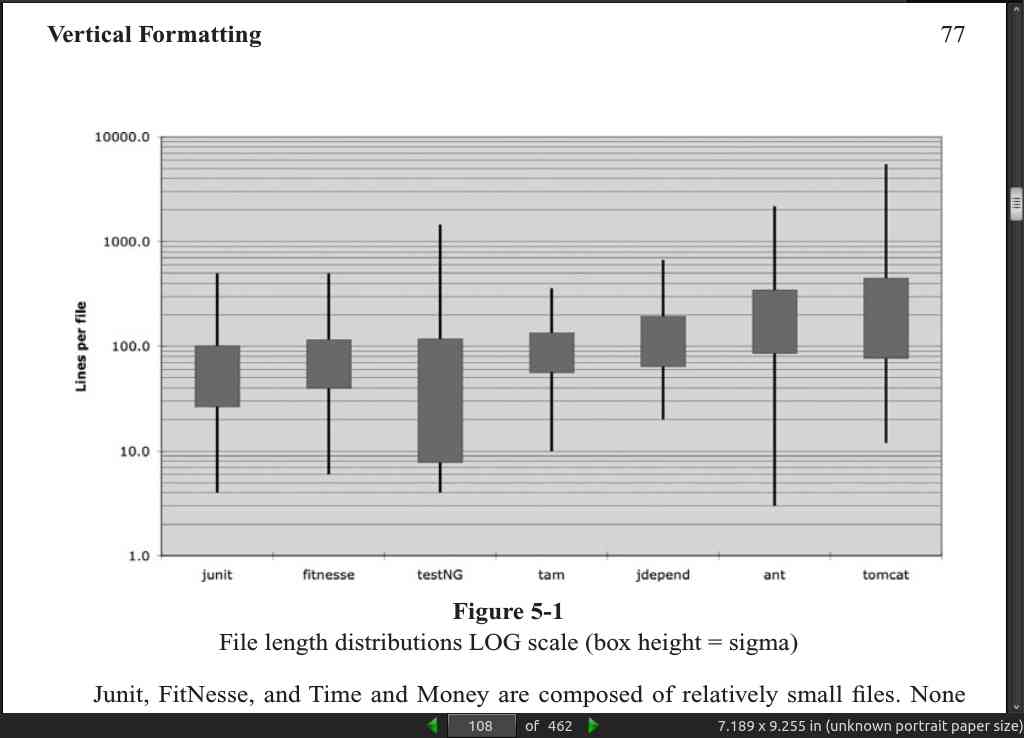
page 113:
- If one function calls another, they should be vertically close, and the caller should be above the callee, if at all possible. This gives the program a natural flow.
page 115:
-
In general we want function call dependencies to point in the downward direction. That is, a function that is called should be below a function that does the calling.2
-
2 This is the exact opposite of languages like Pascal, C, and C++ that enforce functions to be defined, or at least declared, before they are used.
page 116:
· 06: Objects and Data Structures
page 126:
- Objects hide their data behind abstractions and expose functions that operate on that data. Data structure expose their data and have no meaningful functions.
page 128:
-
Procedural code (code using data structures) makes it easy to add new functions without changing the existing data structures. OO code, on the other hand, makes it easy to add new classes without changing existing functions.
-
The complement is also true:
-
Procedural code makes it hard to add new data structures because all the functions must change. OO code makes it hard to add new functions because all the classes must change.
page 132:
-
Objects expose behavior and hide data. This makes it easy to add new kinds of objects without changing existing behaviors. It also makes it hard to add new behaviors to existing objects. Data structures expose data and have no significant behavior. This makes it easy to add new behaviors to existing data structures but makes it hard to add new data structures to existing functions.
-
In any given system we will sometimes want the flexibility to add new data types, and so we prefer objects for that part of the system. Other times we will want the flexibility to add new behaviors, and so in that part of the system we prefer data types and procedures.
· 07: Error Handling
page 137:
- Try to write tests that force exceptions, and then add behavior to your handler to satisfy your tests. This will cause you to build the transaction scope of the try block first and will help you maintain the transaction nature of that scope.
· 08: Boundaries
page 148:
- Learning tests: create tests for a new API you plan on using as a way to learn it.
page 149:
-
The learning tests end up costing nothing. We had to learn the API anyway, and writing those tests was an easy and isolated way to get that knowledge. The learning tests were precise experiments that helped increase our understanding.
-
Not only are learning tests free, they have a positive return on investment. When there are new releases of the third-party package, we run the learning tests to see whether there are behavioral differences.
page 150:
· 09: Unit Tests
· 10: Classes
page 180:
- In an ideal system, we incorporate new features by extending the system, not by making modifications to existing code.
· 11: Systems
page 189:
-
It is a myth that we can get systems “right the first time.” Instead, we should implement only today’s stories, then refactor and expand the system to implement new stories tomorrow.
-
I strongly disagree here. He was just talking about growing from settlement to town to city. OK, sounds good, you couldn’t really plan a city from day one (actually you could, look at some of the places in Dubai and China) but you most certainly can plan and get right a skyscraper the first time. In fact, you have to. Failure in this case is not an option. So, it depends on the size and the scope of the system. I think it is less ‘getting it right’ and more ‘people want different stuff tomorrow.’
page 200:
- Whether you are designing systems or individual modules, never forget to use the simplest thing that can possibly work.
· 12: Emergence
· 13: Concurrency
page 215:
- Main three concurrency problems: producer-consumer, reader-writer, and dining philosophers.
page 218:
- Treat spurious failures as candidate threading issues.
- Get your nonthreaded code working first.
- Make your threaded code pluggable.
- Make your threaded code tunable.
- Run with more threads than processors.
- Run on different platforms.
- Instrument your code to try and force failures.
· 14: Successive Refinement
· 15: JUnit Internals
· 16: Refactoring SerialDate
· 17: Smells and Heuristics
page 340:
- Names in software are 90 percent of what make software readable. You need to take the time to choose them wisely and keep them relevant. Names are too important to treat carelessly.
page 343:
-
the more you can use names that are overloaded with special meanings that are relevant to your project, the easier it will be for readers to know what your code is talking about.
-
The length of a name should be related to the length of the scope. You can use very short variable names for tiny scopes, but for big scopes you should use longer names.