Home · Book Reports · 2018 · Masting Python Regular Expressions

- Author :: Félix López and Víctor Romero
- Publication Year :: 2014
- Read Date :: 2018-07-12
- Source :: Mastering_Python_Regular_Expressions.pdf
designates my notes. / designates important.
Thoughts
“Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems.” -Jamie Zawinski, 1997
This short, sub 100 page, book starts off with a whirlwind history of regular expressions, beginning in 1946, moving up through the Perl implementation, and sets the stage for python’s version.
It covers the basics, the theory behind how patterns are matched, in a language agnostic format. This is perfect if you have little to no foreknowledge of regex. Several diagrams and tables are included that summarize everything you’ll need to get started.
Chapter two moves onto the python specific regex, building patterns, match objects, a cursory look at groups and position, the various compilation flags (re.DOTALL, re.ASCII, etc), and the differences between python 2 and 3.
Chapter three starts to use describe more advanced features such as backreferencing, named groups, overlapping groups, and what the authors call the yes-pattern|no-pattern.
Chapter four is spent detailing the look around functionality: forward and backward, positive and negative. I found this part the most interesting and useful; up until this point the book has been pretty basic.
Lastly, chapter five focuses on performance. It is nice that the authors start out with time honored advice from Donald Knuth:
“Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.”
The performance optimizations given will most likely be irrelevant to someone using regex in a simple program; if you are mining big data, the optimizations in the book might be too simple for you. Still, it rounds out the presentation.
All-in-all I thought it was well worth the read. Quick, to the point, and a few simple, if contrived, examples for each topic.
Exceptional Excerpts
“the look behind mechanism is only able to match fixed-width patterns."
Table of Contents
- 01: Introducing Regular Expressions
- 02: Regular Expressions with Python
- 03: Grouping
- 04: Look Around
- 05: Performance of Regular Expressions
- Pages numbers from the actual book.
· 01: Introducing Regular Expressions
page 6:
- “Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems.” -Jamie Zawinski, 1997
page 13:
Element | Description (for regex with default flags)
--------|-------------------------------------------
. | This element matches any character except newline \n
\d | This matches any decimal digit; this is equivalent to the class [0-9]
\D | This matches any non-digit character; this is equivalent to the class [^0-9]
\s | This matches any whitespace character; this is equivalent to the class [⇢\t\n\r\f\v]
\S | This matches any non-whitespace character; this is equivalent to the class [^ \t\n\r\f\v]
\w | This matches any alphanumeric character; this is equivalent to the class [a-zA-Z0-9_]
\W | This matches any non-alphanumeric character; this is equivalent to the class [^a-zA-Z0-9_]
page 17:
Symbol | Name | Quantification of previous character
------ |-------------- |--------------------------------------
? | Question mark | Optional (0 or 1 repetitions)
* | Asterisk | Zero or more times
+ | Plus sign | One or more times
{n,m} | Curly braces | Between n and m times
- quantifiers are always applied only to the previous token.
page 18:
-
We can also define a certain range of repetitions by providing a minimum and maximum number of repetitions, that is, between three and eight times can be defined with the syntax {4,7}. Either the minimum or the maximum value can be omitted defaulting to 0 and infinite respectively. To designate a repetition of up to three times, we can use {,3}, we can also establish a repetition at least three times with {3,}.
-
Instead of using {,1}, you can use the question mark. The same applies to {0,} for the asterisk * and {1,} for the plus sign +.
page 19:
Syntax | Description
-------|----------------------------------------------------
{n} | The previous character is repeated exactly n times.
{n,} | The previous character is repeated at least n times.
{,n} | The previous character is repeated at most n times.
{n,m} | The previous character is repeated between n and m times (both inclusive).
page 21:
Matcher | Description
------- |------------
^ | Matches at the beginning of a line
$ | Matches at the end of a line
\b | Matches a word boundary
\B | Matches the opposite of \b. Anything that is not a word boundary
\A | Matches the beginning of the input
\Z | Matches the end of the input
· 02: Regular Expressions with Python
page 28:
- Strings in python 2.x

page 34:
- Match every two words and capture them:
>>> pattern = re.compile(r"(\w+) (\w+)")
>>> it = pattern.finditer("Hello⇢world⇢hola⇢mundo")
>>> match = it.next()
>>> match.groups()
('Hello', 'world')
>>> match.span()
(0, 11)
- In the preceding example, we can see how we get an iterator with all the matches. For every element in the iterator, we get a MatchObject, so we can see the captured groups in the pattern, two in this case. We will also get the position of the match.
>>> match = it.next()
>>> match.groups()
('hola', 'mundo')
>>> match.span()
(12, 22)
- match.span shows the location of the match.
page 36:
- The maxsplit parameter specifies how many splits can be done at maximum and returns the remaining part in the result:
>>> pattern = re.compile(r"\W")
>>> pattern.split("Beautiful is better than ugly", 2)
['Beautiful', 'is', 'better than ugly']
- What can we do if we want to capture the pattern too? The answer is to use groups:
>>> pattern = re.compile(r"(-)")
>>> pattern.split("hello-word")
['hello', '-', 'word']
- For example, we’re going to replace the digits in the string with - (dash):
>>> pattern = re.compile(r"[0-9]+")
>>> pattern.sub("-", "order0⇢order1⇢order13")
'order-⇢order-⇢order-'
>>> re.sub('00', '-', 'order00000')
'order--0'
- In the preceding example, we’re replacing zeroes two by two. So, the first two are matched and then replaced, then the following two zeroes are matched and replaced too, and finally the last zero is left intact.
page 37:
- The repl argument can also be a function, in which case it receives a MatchObject as an argument and the string returned is the replacement. For example, imagine you have a legacy system in which there are two kinds of orders. Some start with a dash and the others start with a letter:
• -1234
• A193, B123, C124
- You must change it to the following:
• A1234
• B193, B123, B124
- In short, the ones starting with a dash should start with an A and the rest should start with a B.
>>> def normalize_orders(matchobj):
if matchobj.group(1) == '-': return "A"
else: return "B"
>>> re.sub('([-|A-Z])', normalize_orders, '-1234⇢A193⇢ B123')
'A1234⇢B193⇢B123'
page 41:
- The groupdict method is used in the cases where named groups have been used. It will return a dictionary with all the groups that were found:
>>> pattern = re.compile(r"(?P<first>\w+) (?P<second>\w+)")
>>> pattern.search("Hello⇢world").groupdict()
{'first': 'Hello', 'second': 'world'}
- In the preceding example, we use a pattern similar to what we’ve seen in the previous sections. It captures two groups with the names first and second. So, groupdict returns them in a dictionary.Note that if there aren’t named groups, then it returns an empty dictionary.
page 42:
- span([group]) It’s an operation that gives you a tuple with the values from start and end. This operation is often used in text editors to locate and highlight a search. The following code is an example of this operation:
>>> pattern = re.compile(r"(?P<first>\w+) (?P<second>\w+)?")
>>> match = pattern.search("Hello⇢")
>>> match.span(1)
(0, 5)
page 44:

· 03: Grouping
page 56:
- Backreferences match based on a previously matched group. This matches duplicate words:
>>> pattern = re.compile(r"(\w+) \1")
>>> match = pattern.search(r"hello hello world")
>>> match.groups()
('hello',)
- Use backreferences to manipulate order. We’re saying, “Replace what you’ve matched with the second group, a dash, and the first group”.
>>> pattern = re.compile(r"(\d+)-(\w+)")
>>> pattern.sub(r"\2-\1", "1-a\n20-baer\n34-afcr")
'a-1\nbaer-20\nafcr-34'
- In order to use named groups, we have to use the syntax,(?P
pattern), where the P comes from Python-specific extensions
>>> pattern = re.compile(r"(?P<first>\w+) (?P<second>\w+)")
>>> match = re.search("Hello world")
>>> match.group("first")
'Hello'
>>> match.group("second")
'world'
>>> pattern = re.compile(r"(?P<country>\d+)-(?P<id>\w+)")
>>> pattern.sub(r"\g<id>-\g<country>", "1-a\n20-baer\n34-afcr")
'a-1\nbaer-20\nafcr-34'
- As we see in the previous example, in order to reference a group by the name
in the sub operation, we have to use \g
.
page 58:
- We can also use named groups inside the pattern itself, as seen in the following example:
>>> pattern = re.compile(r"(?P<word>\w+) (?P=word)")
>>> match = pattern.search(r"hello hello world")
>>> match.groups()
('hello',)
Use | Syntax
------------------------------|---------------------
Inside a pattern | (?P=name)
|
In the repl string of the sub | \g<name>
operation |
|
In any of the operations of | match.group('name')
the MatchObject |
page 59:
- we’ve been using groups to create subexpressions, as can be seen in the following example:
>>> re.search("Españ(a|ol)", "Español")
<_sre.SRE_Match at 0x10e90b828>
>>> re.search("Españ(a|ol)", "Español").groups()
('ol',)
- You can see that we’ve captured a group even though we’re not interested in the content of the group. So, let’s try it without capturing, but first we have to know the syntax, which is almost the same as in normal groups, (?:pattern). As you can see, we’ve only added ?:. Let’s see the following example:
>>> re.search("Españ(?:a|ol)", "Español")
<_sre.SRE_Match at 0x10e912648>
>>> re.search("Españ(?:a|ol)", "Español").groups()
()
page 60:
- Flags per group. There is a way to apply the flags we’ve seen in Chapter 2, Regular Expressions with Python, using a special form of grouping: (?iLmsux).
Letter | Flag
-------|-----
i | re.IGNORECASE
L | re.LOCALE
m | re.MULTILINE
s | re.DOTALL
u | re.UNICODE
x | re.VERBOSE
- For example:
>>> re.findall(r"(?u)\w+" ,ur"ñ")
[u'\xf1']
- The above example is the same as:
>>> re.findall(r"\w+" ,ur"ñ", re.U)
[u'\xf1']
· 04: Look Around
page 66:
-
Positive look ahead: This mechanism is represented as an expression preceded by a question mark and an equals sign, ?=, inside a parenthesis block. For example, (?=regex) will match if the passed regex do match against the forthcoming input.
-
Negative look ahead: This mechanism is specified as an expression preceded by a question mark and an exclamation mark, ?!, inside a parenthesis block. For example, (?!regex) will match if the passed regex do not match against the forthcoming input.
-
Positive look behind: This mechanism is represented as an expression preceded by a question mark, a less-than sign, and an equals sign, ?<=, inside a parenthesis block. For example, (?<=regex) will match if the passed regex do match against the previous input.
-
Negative look behind: This mechanism is represented as an expression preceded by a question mark, a less-than sign, and an exclamation mark, ?<!, inside a parenthesis block. For example, (?<!regex) will match if the passed regex do not match against the previous input.
page 67:
- positive look ahead:
>>> pattern = re.compile(r'\w+(?=,)')
>>> pattern.findall("They were three: Felix, Victor, and Carlos.")
['Felix', 'Victor']
- negative look ahead:
>>> pattern = re.compile(r'John(?!\sSmith)')
>>> result = pattern.finditer("I would rather go out with John McLane
than with John Smith or John Bon Jovi")
>>> for i in result:
...print i.start(), i.end()
...
27 31
63 67
page 69:
-
One typical example of look ahead and substitutions would be the conversion of a number composed of just numeric characters, such as 1234567890, into a comma separated number, that is, 1,234,567,890.
-
We can easily start with an almost naive approach with the following highlighted regular expression:
>>> pattern = re.compile(r'\d{1,3}')
>>> pattern.findall("The number is: 12345567890")
['123', '455', '678', '90']
-
We have failed in this attempt.
-
Let’s try to find one, two, or three digits that have to be followed by any number of blocks of three digits until we find something that is not a digit.
page 70:
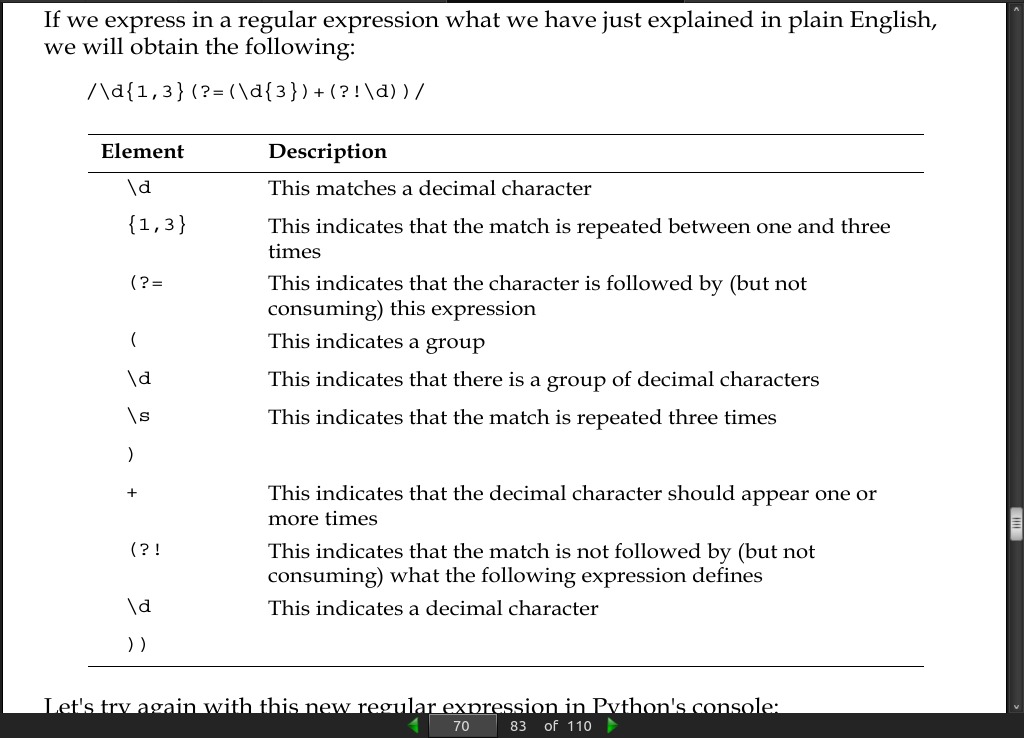
page 71:
>>> pattern = re.compile(r'\d{1,3}(?=(\d{3})+(?!\d))')
>>> pattern.sub(r'\g<0>,', "1234567890")
'1,234,567,890'
- Look behind:
>>> pattern = re.compile(r'(?<=John\s)McLane')
>>> result = pattern.finditer("I would rather go out with John McLane than with
John Smith or John Bon Jovi")
>>> for i in result:
... print i.start(), i.end()
...
32 38
page 72:
-
the look behind mechanism is only able to match fixed-width patterns.
-
If variable-width patterns in look behind are required, the regex module at https://pypi.python.org/pypi/regex can be leveraged instead of the standard Python re module.
page 73:
>>> pattern = re.compile(r'\B@[\w_]+')
>>> pattern.findall("Know your Big Data = 5 for $50 on eBooks and 40%
off all eBooks until Friday #bigdata #hadoop @HadoopNews packtpub.com/
bigdataoffers")
['@HadoopNews']
- The \B is boundary, so the word starts with @, excluding things like email addresses.
page 74:
>>> pattern = re.compile(r'(?<=\B@)[\w_]+')
>>> pattern.findall("Know your Big Data = 5 for $50 on eBooks and 40%
off all eBooks until Friday #bigdata #hadoop @HadoopNews packtpub.com/
bigdataoffers")
['HadoopNews']
-
Uses look behind to exclude the @.
-
The negative look behind mechanism is only able to match fixed-width patterns.
· 05: Performance of Regular Expressions
page 77:
- On December 4, 1974, Donald Knuth, the author of the famous book The Art of Computer Programming, wrote the paper Structured Programming with go-to statements. This well-known quote is extracted from the paper:
- “Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%."
page 78:
- Python comes with a built-in profiler http://docs.python.org/2/library/ profile.html that we can also use to measure the time and the number of calls, among other things:
>>> import cProfile
>>> cProfile.run("alternation('spaniard')")
page 80:
- RegexBuddy (http://www.regexbuddy.com/)
page 81:
- Although it has a couple of downsides, its license is proprietary and the only build available is for Windows.
page 82:
- The regex used in the figure is a perfect example of the importance of how the regex is built. In this case, the expression can be rebuilt as spa(in|niard) so that the regex engine doesn’t have to go back to the start of the string in order to retry the second alternative.